From an earlier experiment, a colleague of mine had created over 100 PDFs that contained random English words and 3 images:

The PDF documents were placed on my website in a directory in May 2005, and links were created that pointed to the PDFs so they could be crawled by any search engine.
In Dec 2005 I used the Yahoo API to discover which of these PDFs had been indexed. I chose the first 100 URLs that were returned and then created a cron job to query the API and public search interface every morning at 3 a.m. Eastern Time. The queries used the "url:" parameter to determine if each URL was indexed or not.
For example, in order to determine if the URL
http://www.cs.odu.edu/~fmccown/lazyp/dayGroup4/page4-39.pdf
is indexed, Yahoo can be queried with
url:http://www.cs.odu.edu/~fmccown/lazyp/dayGroup4/page4-39.pdf
The public search interface will return a web page with a link to the cached version through the "View as HTML" link:
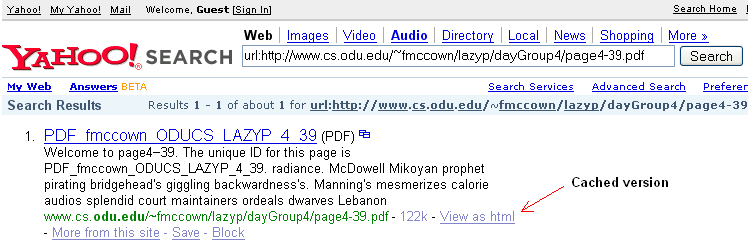
The Yahoo API will also return the cached URL (CacheUrl) for the same query.
Below are the results from my 40 days of querying. The green dots indicate that the URL is indexed but not cached. The blue dots indicate that the URL is cached. White dots indicate the URL is not indexed at all.

Notice that the public search interface and the API show 2 very different results. The red dots in the graph on the right shows where the 2 responses did not agree with each other.
This table reports the percentage of URLs that were classified as either indexed (but not cached), cached, or not indexed:
| Yahoo API | Yahoo Public Search Interface | |
| Indexed only | 3.7% | 2.1% |
| Cached | 89.2% | 91.3% |
| Not indexed | 7.1% | 6.6% |
11% of the time there was a disagreement. For 5 of the URLs the API and public interface disagreed at least 90% of the time!
The inconsistencies discovered between the returned results from the API and public interface suggest that we might get slightly better results using the public interface since it reports 2% more cached URLs. The downside is that any changes made in the results pages may cause our page scrapping code to break.
A further study using different file types (HTML, Word documents, PowerPoint docs, etc.) is needed to be more conclusive. Also it might be useful to use URLs from a variety of websites, not just from one since Yahoo could treat URLs from other sites differently.
I just wanted to be the first person to comment on your blog. It's one of the most amazing blogs I've ever seen... :) I have no idea what an HTML tag is, so I'm not gonna leave one:)
ReplyDeleteI suspect that the author of the first comment is somehow related to the weblog author. But hey - what is family for?
ReplyDeleteAs a blogger, I have been finding your looks at the inside of how Yahoo cache's or does not cache pages very interesting indeed. Keep up the good work.
Besides, I went to college with a McCown, now a Mumford.
Peter, Spell Wrecker in Chief
The Peter Files Blog of Comedy, Commentary, Satire and Eclectic Meanderings