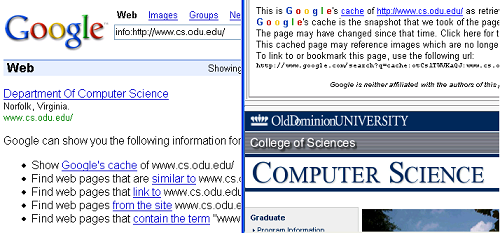
My research focuses on recovering lost websites, and my research group has recently created a tool called Warrick which can reconstruct a website by pulling missing resources from the Internet Archive, Google, Yahoo, and MSN. We have published some of our results using Warrick in a technical report that you can view at arXiv.org.
Warrick is currently undergoing some modifications as we get ready to perform a new batch of website reconstructions. Hopefully I’ll have a stable version of Warrick available for download soon.
Update on 3/20/07:
Warrick has been made available (for quite some time) here and our initial experiments were formally published in Lazy Preservation: Reconstructing Websites by Crawling the Crawlers (WIDM 2006).
No comments:
Post a Comment