We have observed important and beautiful websites emerge and disappear from the web everyday. We believe that archiving the content of all sites is a social necessity and needs to take place now! To this effect we intend to archive all sites, pages and links that come through Hanzo and allow free access to this collection forever.
This sounds a lot like the Internet Archive’s mission:
The Internet Archive is working to prevent the Internet — a new medium with major historical significance — and other "born-digital" materials from disappearing into the past. Collaborating with institutions including the Library of Congress and the Smithsonian, we are working to preserve a record for generations to come.
It's difficult to say when the Hanzo service came online. I found some archived content going back to Nov 2005. They’ll be talking about it at the O'Reilly’s Emerging Technology conference in March and will be launching a public beta of their API.
The contents of the hanzo:web archive are apparently accessible to web crawlers. I couldn’t find a robotos.txt file, and if you do a Google search for "warrick reconstruct" you'll get my Warrick page first and the archived version from hanzo:web second! (I don’t know who archived my page, but thanks!)
Notice the Internet Archive-looking URL:
http://hanzoweb.com/archive/20060104132758/http://www.cs.odu.edu/~fmccown/research/lazy/warrick.html
At the bottom of the page they insert some JavaScript to redirect links back to Hanzo:
<SCRIPT language="Javascript">
<!--
// FILE ARCHIVED ON 20060104132758 AND RETRIEVED FROM
// HANZO:WEB ON 2006-02-21 18:47:35.004450.
// JAVASCRIPT APPENDED BY HANZO:WEB.
// ALL OTHER CONTENT MAY ALSO BE PROTECTED BY COPYRIGHT
var archiveurl = "http://www.hanzoweb.com/archive/20060104132758/";
function rewriteURL(aCollection, sProp) {
var i = 0;
for(i = 0; i < aCollection.length; i++)
if (aCollection[i][sProp].indexOf("mailto:") == -1 &&
aCollection[i][sProp].indexOf("javascript:") == -1)
aCollection[i][sProp] = archiveurl + aCollection[i][sProp];
}
if (document.links) rewriteURL(document.links, "href");
if (document.images) rewriteURL(document.images, "src");
if (document.embeds) rewriteURL(document.embeds, "src");
if (document.body && document.body.background)
document.body.background = archiveurl + document.body.background;
//-->
</SCRIPT>
This is similar to what Internet Archive does with archived pages.
Hanzo allows pages to be tagged. My Warrick page was tagged with “webarchiving”. Below is a screen shot when accessing my Warrick page from the search interface. This is using frames, so the metadata is shown in the upper frame and the page on the bottom.
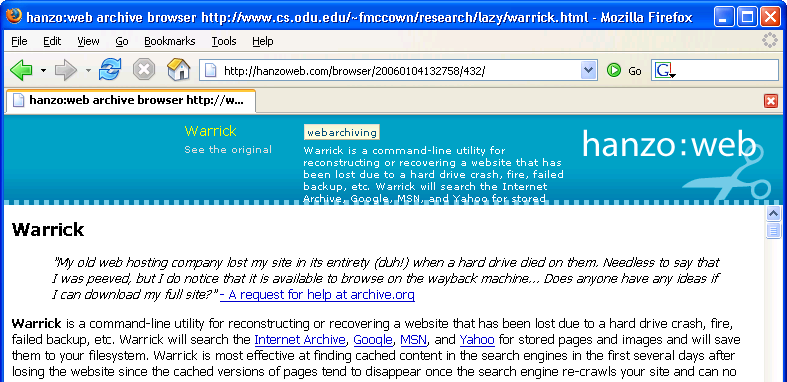
Not only did they have this page already archived, they also had archived several other pages from my website. I can’t tell if there is a way to list all pages they have archived I can search for “fmccown” or “www.cs.odu.edu/~fmccown” using their search interface, and all that shows up is my Warrick page. I assume in the next few months they’ll be adding more info about how to find archived pages.
Not only do they look like the Archive, but they're using the Archive's crawling software, Heretrix.
ReplyDelete