Google has just lost a preliminary injunction against Perfect 10, a website that shows nude photos for a monthly fee. Apparently Perfect 10 doesn’t like it that their images appear in Google Images because the thumbnail images are just the right size for handheld devices. The logic is that mobile users won’t pay for a subscription to Perfect 10 when they can get the same images for free in Google Images. The reason the images appear in Google Images is because they are being harvested from websites of copyright pirates that make illegal copies of the Perfect 10 images.
In my opinion, Google is not really to blame for the copyright infringers. Perfect 10 should be dealing with those people directly and leave Google alone. Although Google states that they will likely just need to remove Perfect 10 photos from Google Images, this could open the door for a lot more litigation. What about all the nude images from hundreds of other websites that are being pirated and placed on indexable websites? It would be wise for Google to have a general policy of keeping their index free of nude photos. In fact, Google would do well to completely separate itself from the pornography industry, an industry that profits on humanity’s baser instincts. (Yes, I do feel strongly on this issue.)
Wednesday, February 22, 2006
Tuesday, February 21, 2006
Ghostsites
Steve Baldwin has a really nice blog called Ghostsites which is dedicated to really old web pages and sites. A few entries that caught my eye:
- Is This the World’s Oldest Active Web Page?
- This Site Proudly Optimized for Netscape 2.0!
- The Museum of E-Failure
hanzo:web = Internet Archive + Furl
I just discovered a new web archiving service called hanzo:web. It is similar to Furl except that they allow you to archive an entire website, not just a single web page. From the site:
This sounds a lot like the Internet Archive’s mission:
It's difficult to say when the Hanzo service came online. I found some archived content going back to Nov 2005. They’ll be talking about it at the O'Reilly’s Emerging Technology conference in March and will be launching a public beta of their API.
The contents of the hanzo:web archive are apparently accessible to web crawlers. I couldn’t find a robotos.txt file, and if you do a Google search for "warrick reconstruct" you'll get my Warrick page first and the archived version from hanzo:web second! (I don’t know who archived my page, but thanks!)
Notice the Internet Archive-looking URL:
http://hanzoweb.com/archive/20060104132758/http://www.cs.odu.edu/~fmccown/research/lazy/warrick.html
At the bottom of the page they insert some JavaScript to redirect links back to Hanzo:
<SCRIPT language="Javascript">
<!--
// FILE ARCHIVED ON 20060104132758 AND RETRIEVED FROM
// HANZO:WEB ON 2006-02-21 18:47:35.004450.
// JAVASCRIPT APPENDED BY HANZO:WEB.
// ALL OTHER CONTENT MAY ALSO BE PROTECTED BY COPYRIGHT
var archiveurl = "http://www.hanzoweb.com/archive/20060104132758/";
function rewriteURL(aCollection, sProp) {
var i = 0;
for(i = 0; i < aCollection.length; i++)
if (aCollection[i][sProp].indexOf("mailto:") == -1 &&
aCollection[i][sProp].indexOf("javascript:") == -1)
aCollection[i][sProp] = archiveurl + aCollection[i][sProp];
}
if (document.links) rewriteURL(document.links, "href");
if (document.images) rewriteURL(document.images, "src");
if (document.embeds) rewriteURL(document.embeds, "src");
if (document.body && document.body.background)
document.body.background = archiveurl + document.body.background;
//-->
</SCRIPT>
This is similar to what Internet Archive does with archived pages.
Hanzo allows pages to be tagged. My Warrick page was tagged with “webarchiving”. Below is a screen shot when accessing my Warrick page from the search interface. This is using frames, so the metadata is shown in the upper frame and the page on the bottom.
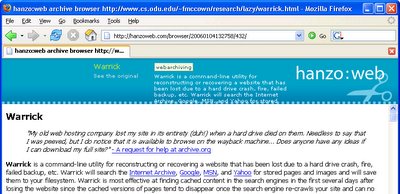
Not only did they have this page already archived, they also had archived several other pages from my website. I can’t tell if there is a way to list all pages they have archived I can search for “fmccown” or “www.cs.odu.edu/~fmccown” using their search interface, and all that shows up is my Warrick page. I assume in the next few months they’ll be adding more info about how to find archived pages.
We have observed important and beautiful websites emerge and disappear from the web everyday. We believe that archiving the content of all sites is a social necessity and needs to take place now! To this effect we intend to archive all sites, pages and links that come through Hanzo and allow free access to this collection forever.
This sounds a lot like the Internet Archive’s mission:
The Internet Archive is working to prevent the Internet — a new medium with major historical significance — and other "born-digital" materials from disappearing into the past. Collaborating with institutions including the Library of Congress and the Smithsonian, we are working to preserve a record for generations to come.
It's difficult to say when the Hanzo service came online. I found some archived content going back to Nov 2005. They’ll be talking about it at the O'Reilly’s Emerging Technology conference in March and will be launching a public beta of their API.
The contents of the hanzo:web archive are apparently accessible to web crawlers. I couldn’t find a robotos.txt file, and if you do a Google search for "warrick reconstruct" you'll get my Warrick page first and the archived version from hanzo:web second! (I don’t know who archived my page, but thanks!)
Notice the Internet Archive-looking URL:
http://hanzoweb.com/archive/20060104132758/http://www.cs.odu.edu/~fmccown/research/lazy/warrick.html
At the bottom of the page they insert some JavaScript to redirect links back to Hanzo:
<SCRIPT language="Javascript">
<!--
// FILE ARCHIVED ON 20060104132758 AND RETRIEVED FROM
// HANZO:WEB ON 2006-02-21 18:47:35.004450.
// JAVASCRIPT APPENDED BY HANZO:WEB.
// ALL OTHER CONTENT MAY ALSO BE PROTECTED BY COPYRIGHT
var archiveurl = "http://www.hanzoweb.com/archive/20060104132758/";
function rewriteURL(aCollection, sProp) {
var i = 0;
for(i = 0; i < aCollection.length; i++)
if (aCollection[i][sProp].indexOf("mailto:") == -1 &&
aCollection[i][sProp].indexOf("javascript:") == -1)
aCollection[i][sProp] = archiveurl + aCollection[i][sProp];
}
if (document.links) rewriteURL(document.links, "href");
if (document.images) rewriteURL(document.images, "src");
if (document.embeds) rewriteURL(document.embeds, "src");
if (document.body && document.body.background)
document.body.background = archiveurl + document.body.background;
//-->
</SCRIPT>
This is similar to what Internet Archive does with archived pages.
Hanzo allows pages to be tagged. My Warrick page was tagged with “webarchiving”. Below is a screen shot when accessing my Warrick page from the search interface. This is using frames, so the metadata is shown in the upper frame and the page on the bottom.
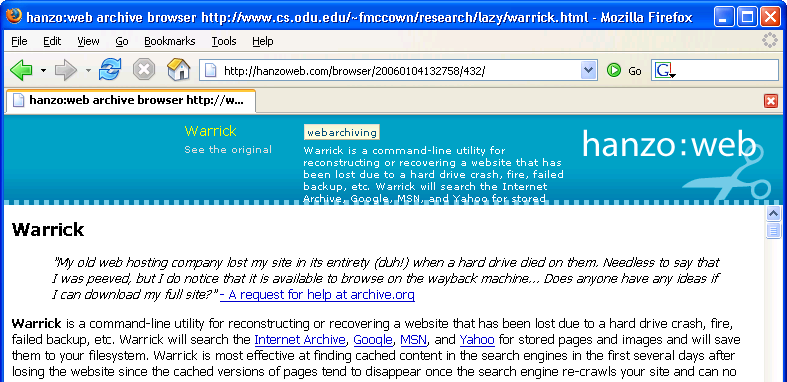
Not only did they have this page already archived, they also had archived several other pages from my website. I can’t tell if there is a way to list all pages they have archived I can search for “fmccown” or “www.cs.odu.edu/~fmccown” using their search interface, and all that shows up is my Warrick page. I assume in the next few months they’ll be adding more info about how to find archived pages.
Friday, February 10, 2006
Some thoughts on robots.txt
The Robots Exclusion Protocol has been around since June 1994, but there is no official standards body or RFC for the protocol. That leaves others free to tinker with it and add their own bells and whistles.
There are numerous limitations to robots.txt that have been noted (see Martijn Koster’s article). A few things that are lacking: ability to specify how frequently server requests should be made, the ideal times to make automated requests, permissions to visit vs. index vs. cache (make available in search engine caches).
According to Matt Cutts, Google supports the “Allow:” directive and wildcards (*) which are not part of the standard. The Google Sitemap team even developed a tool that can be used to ensure compliance with their robots.txt non-standard standard. Matt went on to comment that Google does not support a time delay between requests because some webmasters use values that would only allow Google to crawl 15-20 URLs in a day. Yahoo and MSN support this feature using a “Crawl-delay: XX” directive.
Well, I'm out of thoughts. :) Stay tuned…
There are numerous limitations to robots.txt that have been noted (see Martijn Koster’s article). A few things that are lacking: ability to specify how frequently server requests should be made, the ideal times to make automated requests, permissions to visit vs. index vs. cache (make available in search engine caches).
According to Matt Cutts, Google supports the “Allow:” directive and wildcards (*) which are not part of the standard. The Google Sitemap team even developed a tool that can be used to ensure compliance with their robots.txt non-standard standard. Matt went on to comment that Google does not support a time delay between requests because some webmasters use values that would only allow Google to crawl 15-20 URLs in a day. Yahoo and MSN support this feature using a “Crawl-delay: XX” directive.
Well, I'm out of thoughts. :) Stay tuned…
Wednesday, February 08, 2006
Rank of Graduate Programs in CS
I just found this really cool resource at PhDs.org that helps you rank CS graduate programs:
http://www.phds.org/rankings/computer-science/get_weights
When I set “Program quality has improved recently” to HIGH, ODU appears number 25.
If I set “A SMALL percentage of recent Ph.D.s were granted to U.S. citizens and permanent residents” to HIGH, ODU shoots up to number 6! We certainly are an international school. :)
http://www.phds.org/rankings/computer-science/get_weights
When I set “Program quality has improved recently” to HIGH, ODU appears number 25.
If I set “A SMALL percentage of recent Ph.D.s were granted to U.S. citizens and permanent residents” to HIGH, ODU shoots up to number 6! We certainly are an international school. :)
Thursday, February 02, 2006
Updated C#, VB.NET, Java Comparisons
Today I updated my C# comparison pages for Java and VB.NET:
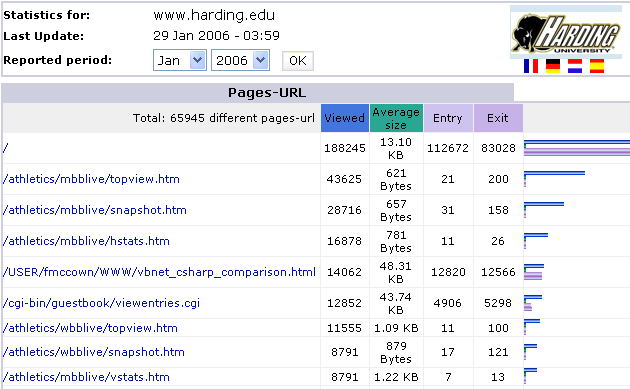
Maintaining these pages is really time-consuming, but I get so much positive feedback that it makes it worth it. A look the server logs shows that the C# vs. VB.NET page is especially popular. In any given month it’s typically the 4th requested URL from the harding.edu website.
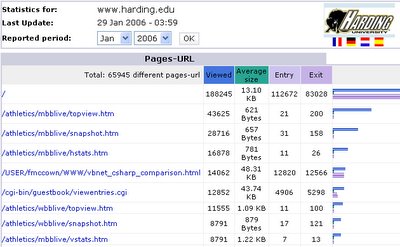
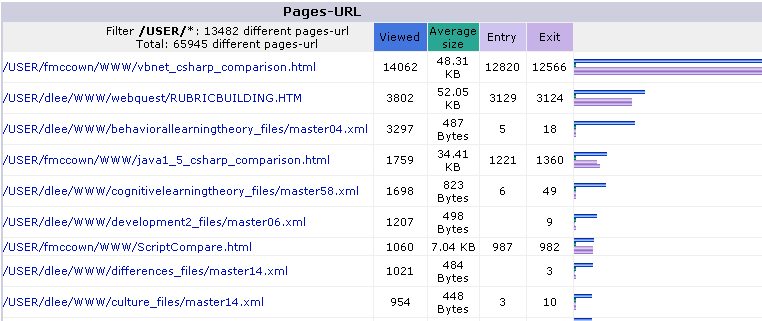
When filtering for just pages produced by faculty members, the C# vs. VB.NET page is first by a factor of 4, and the Java 1.5 vs. C# page is around 4th place.
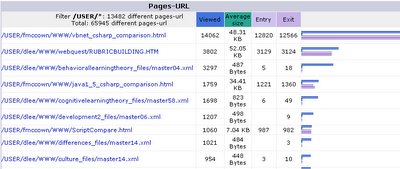
A shocker is my JavaScript vs. VBScript comparison page appearing 7th. I haven’t updated that thing in years, and who is using VBScript anyway? I guess its still getting attention from those die-hard ASP programmers. ;)
Maintaining these pages is really time-consuming, but I get so much positive feedback that it makes it worth it. A look the server logs shows that the C# vs. VB.NET page is especially popular. In any given month it’s typically the 4th requested URL from the harding.edu website.
When filtering for just pages produced by faculty members, the C# vs. VB.NET page is first by a factor of 4, and the Java 1.5 vs. C# page is around 4th place.
A shocker is my JavaScript vs. VBScript comparison page appearing 7th. I haven’t updated that thing in years, and who is using VBScript anyway? I guess its still getting attention from those die-hard ASP programmers. ;)
Subscribe to:
Posts (Atom)