- RB – Larry Johnson
- RB – Willis McGahee
- QB – Jake Plummer
- WR – Donald Driver
- TE – Chris Cooley
- WR – Andre Johnson
- DEF – Cowboys
- K – Josh Brown
- RB – Mike Bell
- QB – Mark Brunnell
- WR – Nate Burleson
- K –
- DEF – Patriots
- TE – Desmond Clark
Monday, August 28, 2006
Bayside League: 2006-2007 season
Thursday, August 24, 2006
Funny Commercials
One of my hobbies is “collecting” commercials. I know that sounds odd. What I mean is I am a big fan of commercials, and I like to download or keep “pointers” to commercials that I think are really hilarious, entertaining, or just plain fantastic. Google Video and YouTube are two of the best sources for commercials. In fact my favorite commercial this year is the Liberty Mutual “pay-it-forward” commercial which is now available on YouTube:
When we got home from church last night, we caught the “World’s Funniest Commercials” on TBS. In general I was disappointed by the crassness and message of many of the commercials, but there were a few gems:
LA Country Fair – "Duh, Ashley, all wool comes from a cow..."
1-800-Got-Junk – “Rat Advertising Trial (R.A.T.)”
Avis: Gansta Rap – “Gotta get that money made”
Solo Mobile: Housewarming – “You are a legend”
Honorable mention: Pacman Puppet Show
All the commercials can be seen in high quality at veryfunnyads.com.
When we got home from church last night, we caught the “World’s Funniest Commercials” on TBS. In general I was disappointed by the crassness and message of many of the commercials, but there were a few gems:
LA Country Fair – "Duh, Ashley, all wool comes from a cow..."
1-800-Got-Junk – “Rat Advertising Trial (R.A.T.)”
Avis: Gansta Rap – “Gotta get that money made”
Solo Mobile: Housewarming – “You are a legend”
Honorable mention: Pacman Puppet Show
All the commercials can be seen in high quality at veryfunnyads.com.
Tuesday, August 22, 2006
The ACLU and nonsectarian prayer
Last week, a federal judge dismissed a Fredericksburg City Council member's lawsuit challenging the council's nonsectarian prayer policy. Ironically, the ACLU of Virginia is fighting in this case to limit the liberties of an individual rather than protect them. It’s not quite so surprising when you learn their opponent is a Christian who desires to use the name “Jesus Christ” in an opening prayer for the city council.
A lawyer friend of mine who is intimately familiar with this case offered the ideal ACLU prayer, guaranteed to be as nonsectarian as possible:
"At this point we would like to call on a genderless, nameless higher power than ourselves and invoke that being (or those beings) intervention (or non-intervention as the case may be) upon this governmental body."
If it ever does come down to that, most of us would rather have no prayer at all. That’s exactly what the ACLU is hoping as well.
Hypertext 2006
 Michael is in
Michael is in - Evaluation of Crawling Policies for a Web-Repository Crawler by McCown and Nelson
- Just-In-Time Recovery of Missing Web Pages by Harrison and Nelson
Lazy Paper accepted to WIDM'06
I got some really good news yesterday- my Lazy Preservation paper (“Lazy Preservation: Reconstructing Websites by Crawling the Crawlers”) was accepted for publication at the WIDM’06 workshop along with Joan’s mod_oai paper. Only 11 of the 51 submissions (21.5%) were accepted which means the workshop participants are going to be getting very familiar with the research aims at ODU. ;-)
WIDM is in Arlington, Virginia on November 10 and is held in conjunction with CIKM’06. This will be a good opportunity for me to visit my sister again in D.C. I was up there a few weeks ago giving the good news about Becky’s pregnancy to my parents (they were visiting from St. Louis). Random event: while I was in D.C., my mom and I ran into Karl Rove at a bookstore- we chatted for a while (Mom’s a fan), and he seemed like a nice guy, but I'm sure most politicians do. Anywho, I’m looking forward to the workshop.
WIDM is in Arlington, Virginia on November 10 and is held in conjunction with CIKM’06. This will be a good opportunity for me to visit my sister again in D.C. I was up there a few weeks ago giving the good news about Becky’s pregnancy to my parents (they were visiting from St. Louis). Random event: while I was in D.C., my mom and I ran into Karl Rove at a bookstore- we chatted for a while (Mom’s a fan), and he seemed like a nice guy, but I'm sure most politicians do. Anywho, I’m looking forward to the workshop.
Thursday, August 17, 2006
Google Analytics
This morning I installed Google Analytics on my blog and ODU website. It’s a free tool that allows me to track how users enter, leave, and navigate my website. It involved simply posting some JavaScript (below) on the pages I wanted to track:
Update on 8/25/06
It's been a week, and I'm now able to see some analysis of my blog and my ODU cs website. The screen below shows a summary of my blog's traffic from Aug 18-24:
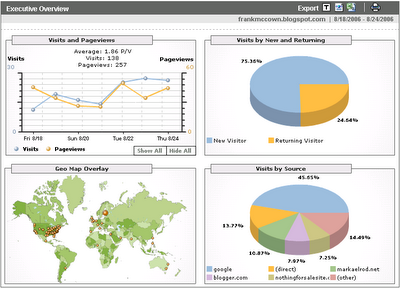
Visitors increased from 11 to 26 during this week, and pageviews ranged from 25-49. Three quarters of the traffic are new visitors (Google is using cookies to track this).
The Geo Map Overlay is fascinating. My blog tends to appeal more to Americans and Europeans: I got only 2 visits from Australia, 1 from South America, and 1 from Africa. There were 14 visits from Tampere, Finland and 9 from Nokia (also in Tampere). The Visits by Source graph shows the Finish hits to be from Timo's nothingforsale.com website where I now have a link pointing to my blog.
Most people find my blog through Google. So what are people searching Google for that lands them on my blog?
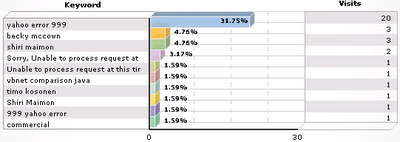 Apparently my blog entry about Yahoo's error 999 is by far the most popular. Searches 1, 4, 5, and 9 will all return this entry in Google's top 10 results. The "shiri maimon" entry doesn't show up in Google until page 3 (top 30 results).
Apparently my blog entry about Yahoo's error 999 is by far the most popular. Searches 1, 4, 5, and 9 will all return this entry in Google's top 10 results. The "shiri maimon" entry doesn't show up in Google until page 3 (top 30 results).
What pages are referring visitors? Apparently Elrod's blog is the biggest referrer so far. This is due to a comment I left on Aug 18.
 What really surprises me is that anyone is visiting frankmccown.com, a website with no content. I did a search for "frank mccown" in Google, and the site came up number one. Come on Google... you guys are supposed to be punishing content-less sites like this, not promoting them. I guess Google's PageRank is far from what they originally published in 1998; there's maybe 1 or 2 links to this page from anywhere on the Web.
What really surprises me is that anyone is visiting frankmccown.com, a website with no content. I did a search for "frank mccown" in Google, and the site came up number one. Come on Google... you guys are supposed to be punishing content-less sites like this, not promoting them. I guess Google's PageRank is far from what they originally published in 1998; there's maybe 1 or 2 links to this page from anywhere on the Web.
My cs website is getting a little more traffic than my blog even though I only have the tracking on a few of the pages. What was most interesting to learn was that Wikipedia was by far the largest referrer, sending me around 60 referrals last week. Most of the referrals are coming from the Internet Archive entry where there's a pointer to Warrick.
The Warrick page received 125 visits and 175 pageviews last week (18 and 25 per day, respectively). Here are some search terms people are using to find Warrick:
<script src="http://www.google-analytics.com/urchin.js" type="text/javascript">It’s going to take a few weeks before there’s any data collected, but I’m really curious to see what this will reveal about the popularity of Warrick since I don’t have access to the CS web server logs.
</script>
<script type="text/javascript">
_uacct = "UA-######-#";
urchinTracker();
</script>
Update on 8/25/06
It's been a week, and I'm now able to see some analysis of my blog and my ODU cs website. The screen below shows a summary of my blog's traffic from Aug 18-24:
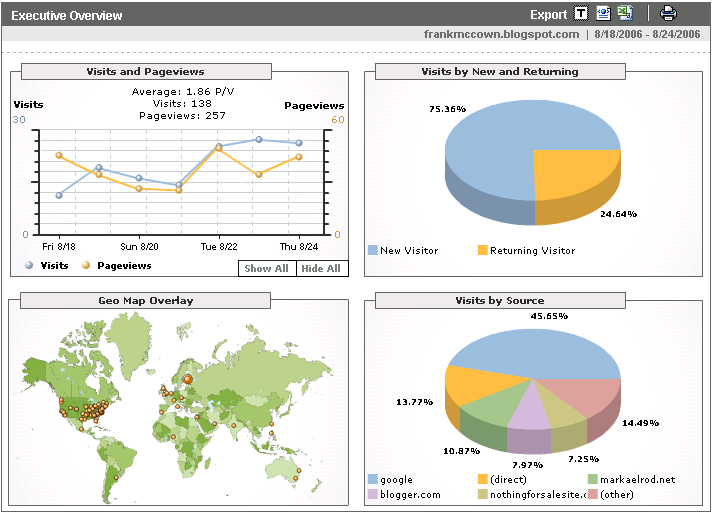
Visitors increased from 11 to 26 during this week, and pageviews ranged from 25-49. Three quarters of the traffic are new visitors (Google is using cookies to track this).
The Geo Map Overlay is fascinating. My blog tends to appeal more to Americans and Europeans: I got only 2 visits from Australia, 1 from South America, and 1 from Africa. There were 14 visits from Tampere, Finland and 9 from Nokia (also in Tampere). The Visits by Source graph shows the Finish hits to be from Timo's nothingforsale.com website where I now have a link pointing to my blog.
Most people find my blog through Google. So what are people searching Google for that lands them on my blog?
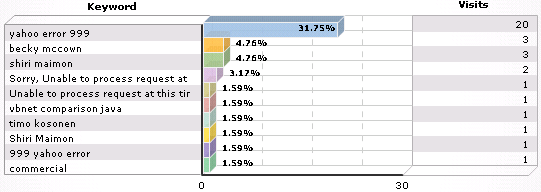 Apparently my blog entry about Yahoo's error 999 is by far the most popular. Searches 1, 4, 5, and 9 will all return this entry in Google's top 10 results. The "shiri maimon" entry doesn't show up in Google until page 3 (top 30 results).
Apparently my blog entry about Yahoo's error 999 is by far the most popular. Searches 1, 4, 5, and 9 will all return this entry in Google's top 10 results. The "shiri maimon" entry doesn't show up in Google until page 3 (top 30 results).What pages are referring visitors? Apparently Elrod's blog is the biggest referrer so far. This is due to a comment I left on Aug 18.
 What really surprises me is that anyone is visiting frankmccown.com, a website with no content. I did a search for "frank mccown" in Google, and the site came up number one. Come on Google... you guys are supposed to be punishing content-less sites like this, not promoting them. I guess Google's PageRank is far from what they originally published in 1998; there's maybe 1 or 2 links to this page from anywhere on the Web.
What really surprises me is that anyone is visiting frankmccown.com, a website with no content. I did a search for "frank mccown" in Google, and the site came up number one. Come on Google... you guys are supposed to be punishing content-less sites like this, not promoting them. I guess Google's PageRank is far from what they originally published in 1998; there's maybe 1 or 2 links to this page from anywhere on the Web.My cs website is getting a little more traffic than my blog even though I only have the tracking on a few of the pages. What was most interesting to learn was that Wikipedia was by far the largest referrer, sending me around 60 referrals last week. Most of the referrals are coming from the Internet Archive entry where there's a pointer to Warrick.
The Warrick page received 125 visits and 175 pageviews last week (18 and 25 per day, respectively). Here are some search terms people are using to find Warrick:
- google api convert documents to HTML
- Warrick
- Warrick website download
- Warrick archive.org
- warrick perl
- cached archive website
- recover website from google cache
- google cache website recovery
Wednesday, August 16, 2006
Little McCown on the way
I just can’t keep it a secret anymore – Becky is seven weeks pregnant! The appointment with the OBGYN went really well this morning, and, God willing, we are expecting our first little McCown on April 5. That’s when I’ll be in the thick of writing my dissertation, so it will be a really exciting and challenging time! :)
Nothing for sale
When my friend Timo Kosonen emailed me back in January 2006 about his website http://www.nothingforsalesite.com/, I emailed him back saying that he was crazy- who would pay something for nothing? His idea roughly mirrored the http://www.milliondollarhomepage.com/ idea where people spent one dollar per pixel for on-screen real estate. Although it worked out well for the million dollar guy, I wasn’t so sure it would work out the same for Timo.
Well, Timo got some press out of it and was able to make a few hundred dollars (which he applied to his wedding). Not bad for a Harding grad. ;)
Way to go, Timo!
Well, Timo got some press out of it and was able to make a few hundred dollars (which he applied to his wedding). Not bad for a Harding grad. ;)
Way to go, Timo!
Tuesday, August 15, 2006
Torrance Daniels in Philly

Torrance Daniels (“Tank”) is the first player from Harding University to possibly play in the NFL. Right now he’s in training camp with the Philadelphia Eagles. Although I’m no Eagles fan (go Cowboys!), I’ll be pulling for him.
Update on 9/8/06:
It looks like Tank will be on the Eagle's practice squad. Not bad.
Update on 11/21/06:
Tank is now a starter, thanks to the season-ending injury to McNabb.
Update on 11/30/06:
Tank started last Sunday evening against the Colts and made the first tackle of the night on the opening kick-off. There's an article about it on the Harding website.
Friday, August 11, 2006
AOL releases search queries
On Sept 28, 2006, AOL released the search histories of more than 650,000 of its users (21 million queries) on its new research website. Although the data was stripped of personal identifiers, it still made privacy advocates extremely upset. AOL issued an apology 10 days later and yanked the data from their site, but it had already been replicated.
For a researcher involved in information retrieval, this data is a gold mine. Most researchers don’t have access to data like this. Unless you work for a search engine, you have to rely on search data from your institution or beg for it from other locations.
On the other hand, some search data could be linked to specific individuals, and I can see why that would be alarming to some. Perhaps there’s a middle ground? What if location data could be randomly swapped? For example, a search for “boston hair cut” could be changed to “denver hair cut”. Although this would make the location information worthless, all the other important information (query length, word length, subject matter) would still be present. Other heuristics could be applied to muddle the location. Of course this doesn’t address all the privacy issues, but it’s a start.
Many of the queries are very disturbing. Many of the queries deal with pornography, grief, and revenge. The queries are like the random private thoughts of their owners. Although they would likely never mutter this stuff to a friend, they have no problems entering it into a search box. One thing that is very clear, there are a lot of hurting people out there.
What I also found very interesting was the way people make their queries. The lengths of many queries are very long. Users are apparently adding more words to get better precision. As the Web has gotten much larger, it has become necessary to use more words. Just six years ago a long query would result in very few hits, but not anymore. Also people sometimes use slang or misspellings which would likely match fewer results. For example, one user entered “u” in several queries where “you” would obviously be more appropriate. Search engines may need to adopt to the use of slang and make automatic substitutions when possible.
It’s really too bad that AOL has received so much heat for what has happened, especially since other companies like Excite and AltaVista have done the same thing in the past. The difference today is that we are much more aware of privacy issues, and the queries are becoming much more tuned to individuals. I would still like to see Google, MSN, Yahoo, and others also give up some detailed search data like this in the future.
For a researcher involved in information retrieval, this data is a gold mine. Most researchers don’t have access to data like this. Unless you work for a search engine, you have to rely on search data from your institution or beg for it from other locations.
On the other hand, some search data could be linked to specific individuals, and I can see why that would be alarming to some. Perhaps there’s a middle ground? What if location data could be randomly swapped? For example, a search for “boston hair cut” could be changed to “denver hair cut”. Although this would make the location information worthless, all the other important information (query length, word length, subject matter) would still be present. Other heuristics could be applied to muddle the location. Of course this doesn’t address all the privacy issues, but it’s a start.
Many of the queries are very disturbing. Many of the queries deal with pornography, grief, and revenge. The queries are like the random private thoughts of their owners. Although they would likely never mutter this stuff to a friend, they have no problems entering it into a search box. One thing that is very clear, there are a lot of hurting people out there.
What I also found very interesting was the way people make their queries. The lengths of many queries are very long. Users are apparently adding more words to get better precision. As the Web has gotten much larger, it has become necessary to use more words. Just six years ago a long query would result in very few hits, but not anymore. Also people sometimes use slang or misspellings which would likely match fewer results. For example, one user entered “u” in several queries where “you” would obviously be more appropriate. Search engines may need to adopt to the use of slang and make automatic substitutions when possible.
It’s really too bad that AOL has received so much heat for what has happened, especially since other companies like Excite and AltaVista have done the same thing in the past. The difference today is that we are much more aware of privacy issues, and the queries are becoming much more tuned to individuals. I would still like to see Google, MSN, Yahoo, and others also give up some detailed search data like this in the future.
Wednesday, August 09, 2006
Crawling the Web is very, very hard…
- The website’s root URL not redirect the crawler to a URL that is on a different host. If it does, the new URL should replace the old website URL.
- The website’s root URL should not appear to be a splash page for a website on a different host or indicate that the website has moved to a different host. If it does, the new URL should replace the old website URL.
- The website should not have all of its contents blocked by robots.txt. If some directories are blocked, that’s ok.
- The website’s root URL should not have a noindex/nofollow meta tag which would prevent a crawler from grabbing anything else on the website.
- The website should not have any more than 10K resources.
The restrictions seem very straightforward, but in practice they are very time consuming to enforce. Requirement 2 requires me to manually visit the site. Did I mention not all the sites are in English? That makes it even more difficult. Requirement 3 means I have to manually examine the robots.txt. Req. 4 requires manually examination of the root page, and req. 5 means I have to waste several days crawling a site before I know if it is too large or not.
I guess I could build a tool for req 3 and 4, but I’m not in the mood.
Anyway, I ended up making about 50 replacements (at least) and starting my crawls over again. Now I finally have 300 websites that meet my requirements.In the past I’ve used Wget to do my crawling, but I’ve decided to use Heritrix since it has quite a few useful features missing from Wget. But Heritrix isn’t perfect. I made a suggestion that Heritrix show the number of URLs from each host remaining in the frontier when examining a crawl report:
http://sourceforge.net/tracker/index.php?func=detail&amp;aid=1533116&group_id=73833&atid=539102
The other difficulty with Heritrix is in extracting what you have crawled. I will need to write a script that will build an index into the ARC files so I can quickly extract data for a website. Since all the crawl data is merged into a series of ARC files, it is really difficult to throw away crawl data for a website you aren’t interested in. I could write a script to do it, but at this point it’s not worth my time.
Tuesday, August 08, 2006
CiteULike - a second brain for researchers
Today I discovered a new free tool for researchers to manage their references. It’s called CiteULike, and it’s been around since 2004. Richard Cameron created the site and intends to keep it free.
I was able to upload all my BibTeX entries without any difficulties. I can now tag each entry so I can quickly see what papers are relevant to a particular subject. For example, here are all the papers I have tagged for web-archiving:
http://www.citeulike.org/user/fmccown/tag/web-archiving
CiteULike is useful for finding out about new research in your area. For example, this user apparently has many of the same interests as me, and I found several new papers by browsing his library:
http://www.citeulike.org/user/ChaTo/
It’s cool because I can even see comments that users have made about specific papers.
Now when I come across a new paper, I can add it to my CiteULike library and jot a quick note about it and not worry months later when I need to find the paper. And now instead of emailing Michael my BibTeX file, he can download the whole thing directly from the Web.
I was able to upload all my BibTeX entries without any difficulties. I can now tag each entry so I can quickly see what papers are relevant to a particular subject. For example, here are all the papers I have tagged for web-archiving:
http://www.citeulike.org/user/fmccown/tag/web-archiving
CiteULike is useful for finding out about new research in your area. For example, this user apparently has many of the same interests as me, and I found several new papers by browsing his library:
http://www.citeulike.org/user/ChaTo/
It’s cool because I can even see comments that users have made about specific papers.
Now when I come across a new paper, I can add it to my CiteULike library and jot a quick note about it and not worry months later when I need to find the paper. And now instead of emailing Michael my BibTeX file, he can download the whole thing directly from the Web.
Thursday, August 03, 2006
Yahoo transforming FRAME tags
The past several months I’ve been ramping-up for a huge experiment where I’ll be reconstructing several hundred websites. I’ve been learning to use Heritrix and process ARC files, and I’ve been periodically tweaking Warrick. Today I found out that Yahoo has changed the way it caches HTML pages that contain frames.
For example, the page at http://www.harding.edu/comp/ contains the following HTML:
<FRAMESET COLS="195,*" FRAMEBORDER=no FRAMESPACING=0>
<FRAME SRC=menu.html NAME="MENU" MARGINWIDTH=0 MARGINHEIGHT=0>
<FRAME SRC=welcome.html NAME="MAIN">
</FRAMESET>
In Yahoo’s cached page for this URL, the FRAME tags are converted to the following (I’ve added some white space for readability):
<frameset rows="200,*"><frame scrolling="no" noresize="" frameborder="0" marginwidth="0" marginheight="0" src="http://216.109.125.130/search/cache?.intl=us&u=www.harding.edu%2fcomp%2f&
w=%22harding+.edu%22&d=XS7fRmP9NNYx&origargs=p%3durl%253Ahttp%253A%252F%252F
www.harding.edu%252Fcomp%252F%26toggle%3d1%26ei%3dUTF-8%26_intl%3dus&frameid=-1">
<FRAMESET COLS="195,*" FRAMEBORDER=no FRAMESPACING=0>
<frame security="restricted" MARGINHEIGHT="0" MARGINWIDTH="0" NAME="MENU" SRC="http://216.109.125.130/search/cache?.intl=us&u=www.harding.edu%2fcomp%2f&
w=%22harding+.edu%22&d=XS7fRmP9NNYx&origargs=p%3durl%253Ahttp%253A%252F%252F
www.harding.edu%252Fcomp%252F%26toggle%3d1%26ei%3dUTF-8%26_intl%3dus&frameid=1" >
<frame security="restricted" NAME="MAIN" SRC="http://216.109.125.130/search/cache?.intl=us&u=www.harding.edu%2fcomp%2f&
w=%22harding+.edu%22&d=XS7fRmP9NNYx&origargs=p%3durl%253Ahttp%253A%252F%252F
www.harding.edu%252Fcomp%252F%26toggle%3d1%26ei%3dUTF-8%26_intl%3dus&frameid=2" >
</frameset></FRAMESET>
Yahoo is placing their own FRAMESET tags around mine and loading the two column frames with pages directly from their cache. Notice the use of security="restricted" within the FRAME tag which tells the browser to place security constraints on the frame sources; this disables any JavaScript in my pages.
While this conversion of FRAME tags makes the page easier to view from their cache, it completely destroys the original HTML. There’s no way I can even parse through the arguments to tell what URL used to be in the SRC attribute. ARG! Now I’m going to have to add a rule to Warrick that tells it to ignore Yahoo cached pages that contain FRAME tags. Google and MSN have yet to implement this “trick”, and hopefully they never do.
For example, the page at http://www.harding.edu/comp/ contains the following HTML:
<FRAMESET COLS="195,*" FRAMEBORDER=no FRAMESPACING=0>
<FRAME SRC=menu.html NAME="MENU" MARGINWIDTH=0 MARGINHEIGHT=0>
<FRAME SRC=welcome.html NAME="MAIN">
</FRAMESET>
In Yahoo’s cached page for this URL, the FRAME tags are converted to the following (I’ve added some white space for readability):
<frameset rows="200,*"><frame scrolling="no" noresize="" frameborder="0" marginwidth="0" marginheight="0" src="http://216.109.125.130/search/cache?.intl=us&u=www.harding.edu%2fcomp%2f&
w=%22harding+.edu%22&d=XS7fRmP9NNYx&origargs=p%3durl%253Ahttp%253A%252F%252F
www.harding.edu%252Fcomp%252F%26toggle%3d1%26ei%3dUTF-8%26_intl%3dus&frameid=-1">
<FRAMESET COLS="195,*" FRAMEBORDER=no FRAMESPACING=0>
<frame security="restricted" MARGINHEIGHT="0" MARGINWIDTH="0" NAME="MENU" SRC="http://216.109.125.130/search/cache?.intl=us&u=www.harding.edu%2fcomp%2f&
w=%22harding+.edu%22&d=XS7fRmP9NNYx&origargs=p%3durl%253Ahttp%253A%252F%252F
www.harding.edu%252Fcomp%252F%26toggle%3d1%26ei%3dUTF-8%26_intl%3dus&frameid=1" >
<frame security="restricted" NAME="MAIN" SRC="http://216.109.125.130/search/cache?.intl=us&u=www.harding.edu%2fcomp%2f&
w=%22harding+.edu%22&d=XS7fRmP9NNYx&origargs=p%3durl%253Ahttp%253A%252F%252F
www.harding.edu%252Fcomp%252F%26toggle%3d1%26ei%3dUTF-8%26_intl%3dus&frameid=2" >
</frameset></FRAMESET>
Yahoo is placing their own FRAMESET tags around mine and loading the two column frames with pages directly from their cache. Notice the use of security="restricted" within the FRAME tag which tells the browser to place security constraints on the frame sources; this disables any JavaScript in my pages.
While this conversion of FRAME tags makes the page easier to view from their cache, it completely destroys the original HTML. There’s no way I can even parse through the arguments to tell what URL used to be in the SRC attribute. ARG! Now I’m going to have to add a rule to Warrick that tells it to ignore Yahoo cached pages that contain FRAME tags. Google and MSN have yet to implement this “trick”, and hopefully they never do.
Subscribe to:
Comments (Atom)