The fall semester has just begun, and I again find myself wishing I was back in front of a classroom. As I contemplate returning to teaching next fall (God willing), there are several things I’d like to do differently. Here are three nuggets I have come across recently that have gotten me thinking about next fall:
1) Pair Programming
Pair programming is a relatively new way of teaching students how to program in CS1 classes. I first learned of pair programming in a recent CACM article entitled
"Pair Programming Improves Student Retention, Confidence and Program Quality" by McDowell et al (2006). McDowell has
written on the topic since 2002 and even provides a
video on how to teach pair programming.
In McDowell's experiments, they found that more students completed their course, were more satisfied with their work, and stuck with the CS major than students that had to program independently. They also found that the paired students performed similarly on the final exams which means the paired students were learning to program just as well as the non-paired students. The article also discusses how this could be useful for retaining women in CS.
Like every other university,
Harding has seen a downward trend in the number of CS majors over the last several years. I think paired programming may be one of the tools we could use to assist us in building back up enrollment. I’m excited to try it in my introduction to programming classes soon.
2) Programming with Alice
Becky recently met an instructor who was teaching middle school and high school teachers about
Alice, an alternative programming language which teaches programming by manipulating objects in 3D space. When the instructor leaned that Becky’s husband taught programming courses, he handed her an intro to Alice
textbook which she passed on to me.
Alice was developed at
Carnegie Mellon, but it's soon to be
overhauled by Electronic Arts which will give it a really crisp look that the XBox generation has learned to expect. Alice allows students to quickly get an animation running without the boring details of variable declarations and semicolons.
I’d really like to teach Alice to a group of students who have no programming background and see how they do. If I can get them excited about Alice, I may be able to get them excited about computer science.
3) Limit wireless Internet access during class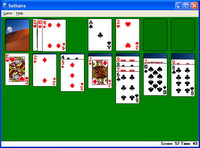 Dennis Adams
Dennis Adams wrote a fantastic Viewpoint piece entitled "
Wireless Laptops in the Classroom (and the Sesame Street Syndrome)" in the September issue of the CACM (2006). Adams, a professor at the University of Houston, opened the article with two examples of “laptops gone wild” in the classroom: a 2002 school brochure which inadvertently contained a photo of a student playing Solitaire while his unaware professor lectured, and 2) a Wall Street Reporter who
witnessed several students using chat rooms, IM, and surfing the Web while Adams lectured.
Adams rightly points out that professors need an off button- a way to turn off wireless access or at least limit access during class. Professors cannot be expected to compete with Google, IM, Solitaire, FaceBook, et al. during their lectures or provide constant
infotainment. No professor, no matter how good, can compete with the infinite number of distractions that the Internet places just inches in front of a student. Adams is
not alone in his assessment.
I have personally used embarrassment tactics as a means to ensure only proper use of laptops while I lectured, and I’ve had some modest success. I called out one of my students who was using MS Paint to create a picture while I lectured, and every day after that he sat very alertly. I’ve been fortunately enough to teach to small classrooms where it’s easy for me to roam and see what my students are doing, but such a strategy certainly doesn’t work in large classroom settings.
Someone is going to create some software that allows only limited Internet connectivity during class, and that person is going to make a killing. And of course the guy who invents the software to circumvent the policing software is going to be the next
Shawn Fanning.







 Money Magazine has listed software engineering as the number one
Money Magazine has listed software engineering as the number one  This morning I sat in the audience during the taping of the
This morning I sat in the audience during the taping of the 
 Today is the five year anniversary of the
Today is the five year anniversary of the 





 Michael is in
Michael is in 




{kind=link}